Horizontal flips as independent samples - kernels viewpoint of data augmentation
Insights into data augmentation in the kernel regime
Solveable models of data augmentation
Data augmentation has long stood as a machine learning trick for getting “free” samples, and with the most highly powered models quickly running out of raw training data, it seems ripe to start exploring the funamentals of data augmentation, before we start feeding in garbage into the models (as the ML addage goes). To explore this, I believe we should be asking: when exactly are augmented samples helpful? How many augmented samples should we train on, given a fixed budget? What type of augment should we train on?
The current state of data augmentation literature partially answers the “when are augmented samples helpful question” by describing the invariances that get baked into the model: if a target function has some invariance, a model representing it will often have an increase in performance. However, this theory is largely irrespective of how many augmented samples are required, with no clear interpolation between “baseline invariance gained by natural samples” and “full invariance gained with augmented samples.” This isn’t to say the results are somehow bad, I just wanted a deeper picture of what happens in the world of data augmentation that the current literature provided.1
As someone who has grown to appreciate learning curves—graphs of test error versus number of samples—I saught out to empirically see how much any individual augmented sample actually increases the performance of a network, building any theory off of the empirical findings. I ran three of the most common data augmentation techniques (rotations, random cropping, and horizontal flips) on subsets of CIFAR10 with some simple models: a ReLU NTK and Convolutional NTK.
Why analyze kernels? I had an early hypothesis that kernels would gain nothing from augmented samples, with the improvements in performance being specific to feature-learning networks.2 If kernels were able to get lower test error, it opens the door to a kernel-theory of data augments, which I have yet to see.
To give the punchline early, kernels do noticably improve (at least on CIFAR10 subtasks like cat vs dog) when using specifically data augmented by horizontal flips, not rotations, nor cropping. As a sidenote, I haven’t been able to come up with any solid theory to back up the rationale for this finding, but I have some unpolished ideas that I’ll share at the end of the post.
This post will first give some background on the non-horizontal flips trials I did before exploring H-flips. Skip this “Initial findings” section if you’re not interested in the data augments that turned up negative results.
Initial findings
This line of work started with a visit to NeurIPS, wherein I attended a workshop discussing invariances in geometric machine learning. Feeling inspired, I took a guess—if the size of our data augmentation group (when applicable) contains total elements, the performance of any network will cap out around . This was based off of ideas within the workshop in addition to later readings of the rank of groups.
I started off with the neural tangent kernel (NTK) of a shallow ReLU network, something that I had been familiar with folloing my recent publication, as I knew theory was more likely to come from a ReLU’s NTK rather than one of a convolutional model.
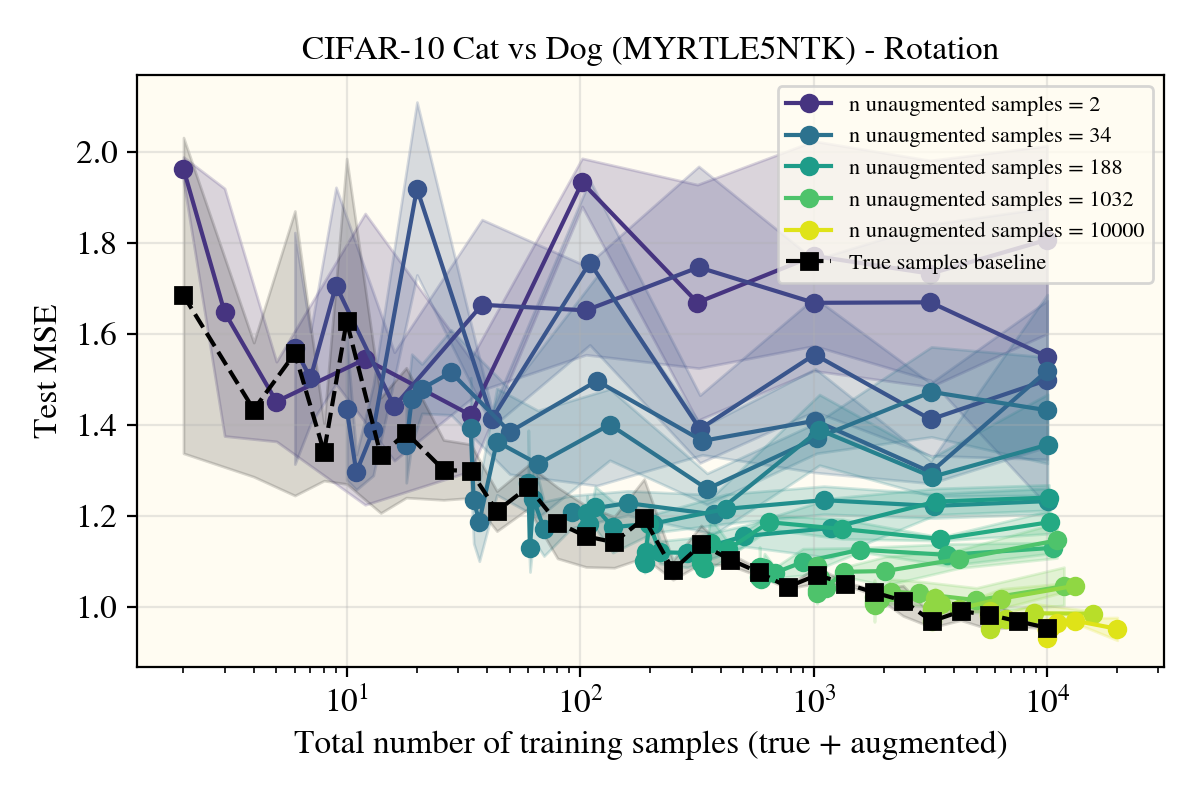
I first trained on airplane vs frog (6), which is to my knowledge the easiest task for CIFAR10, with rotations as my augment of choice, having a clean group size when there were a finite number of potential angles to augment with.
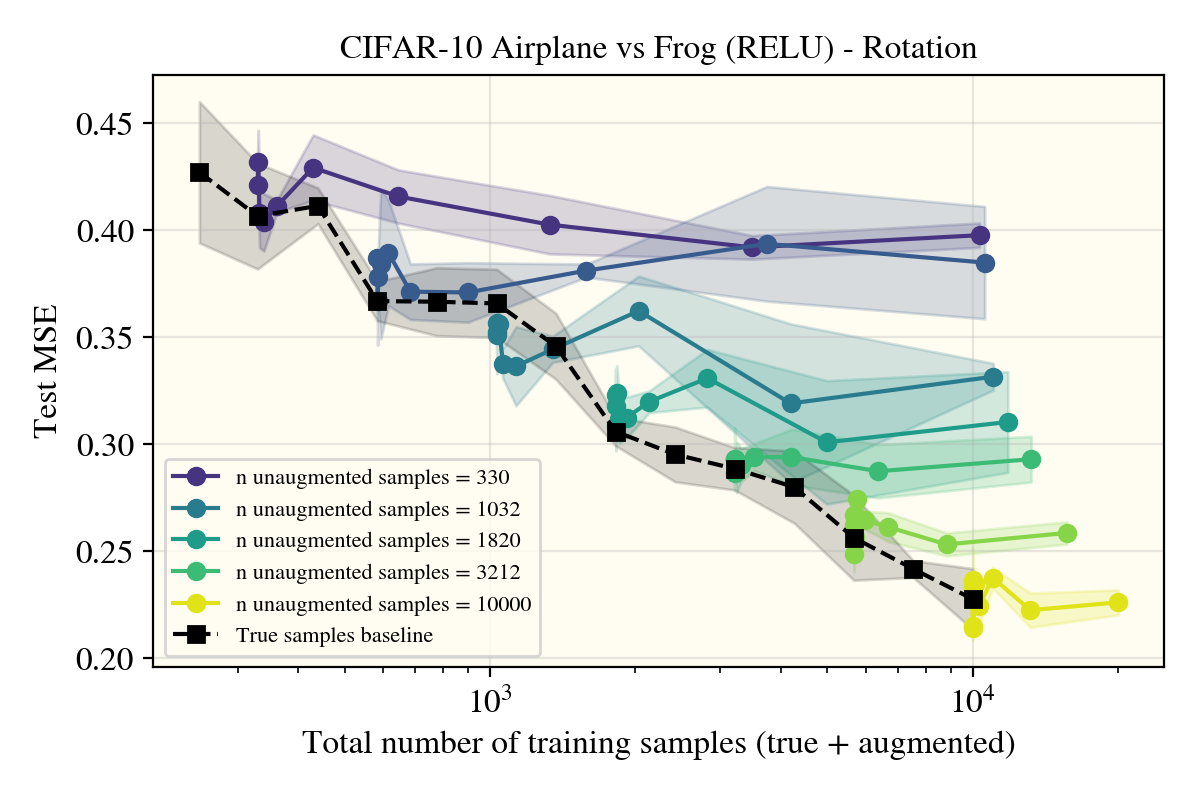
Surprisingly, there is no noticable difference between the kernel performance when applying (rotational) data augments, at least on this task!
There could be a few effects explaining this: the chosen task was too easy (notably, the color (constant mode) is quite distinct between planes and frogs), the choice of kernel make rotations not affect performance, or maybe it was a poor choice of data augment. As it turns out, only the last one was correct, but for correctness, I’ll go through each of these individually.
Task and kernel changes
Was the task too easy? Perhaps! I wasn’t a strong believer that this was true; despite the task being completely different, there wasn’t any strong evidence in my mind that a change in dataset/target function would affect the fundamental affect I was seeing with rotations not providing any gains. At most, I expected something miniscule, but for completeness, I changed the target function to be the notorious cat vs dog dataset.
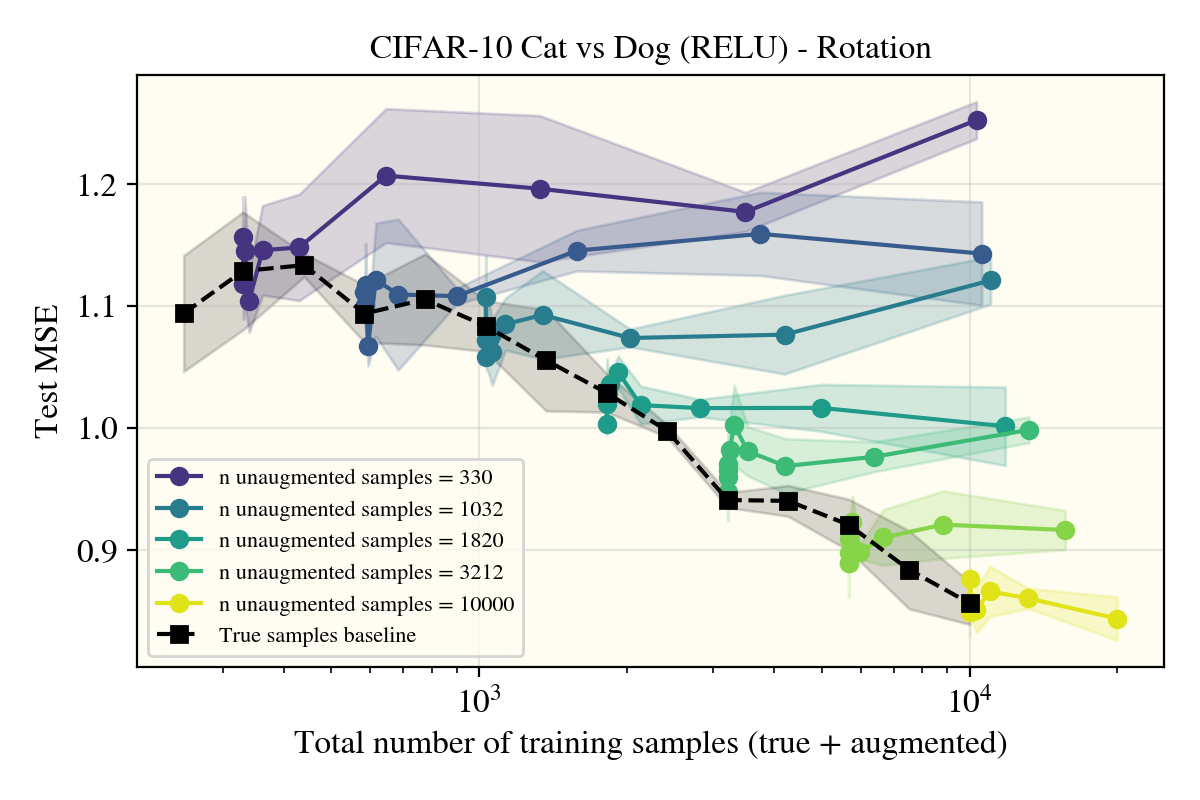
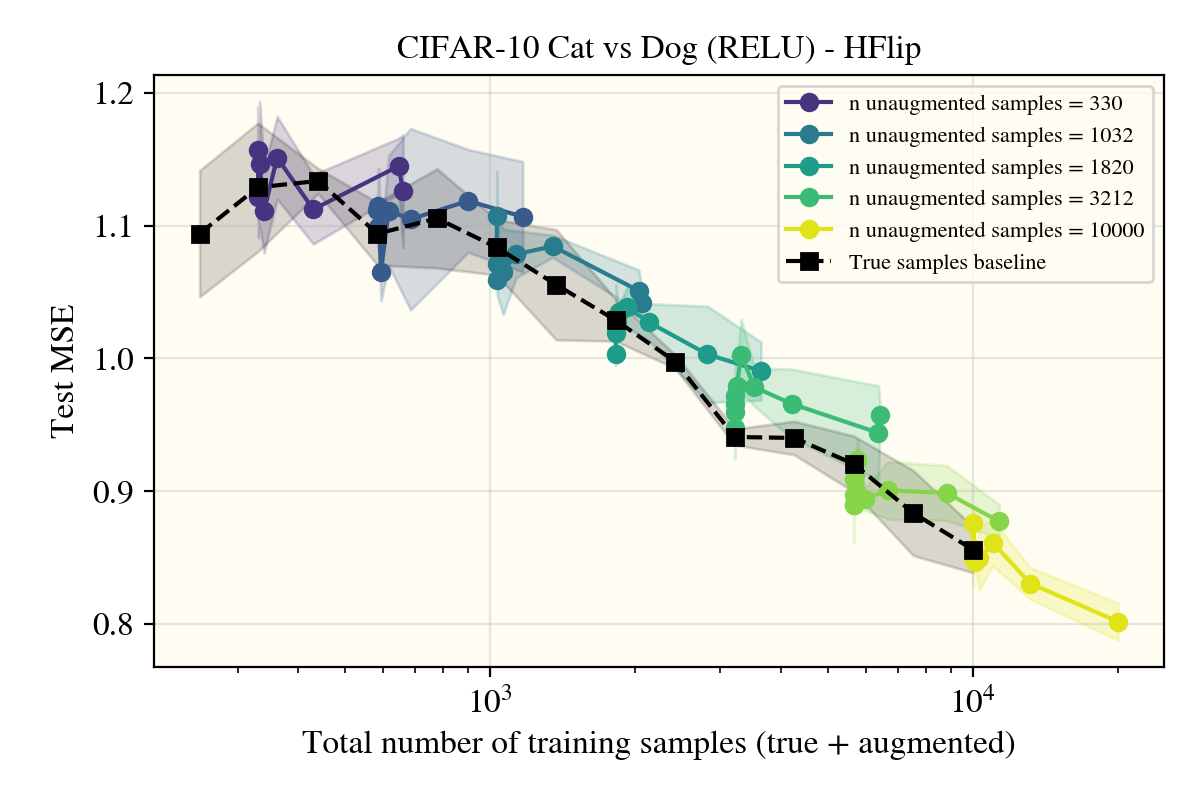
That didn’t work, so I largely dropped the group rank line of questioning, but maybe the results I saw had something to do with the kernel? Despite stronger theoretical tractability, MLPs haven’t been seriously used for vision tasks since convolutional networks were conceived. Without any strong empirical results, it makes sense that we can take a step away from the more theoretical lands for now, so I decided to get a NTK of a Myrtle5 (convolutional network) architecture and see how that change affected performance.
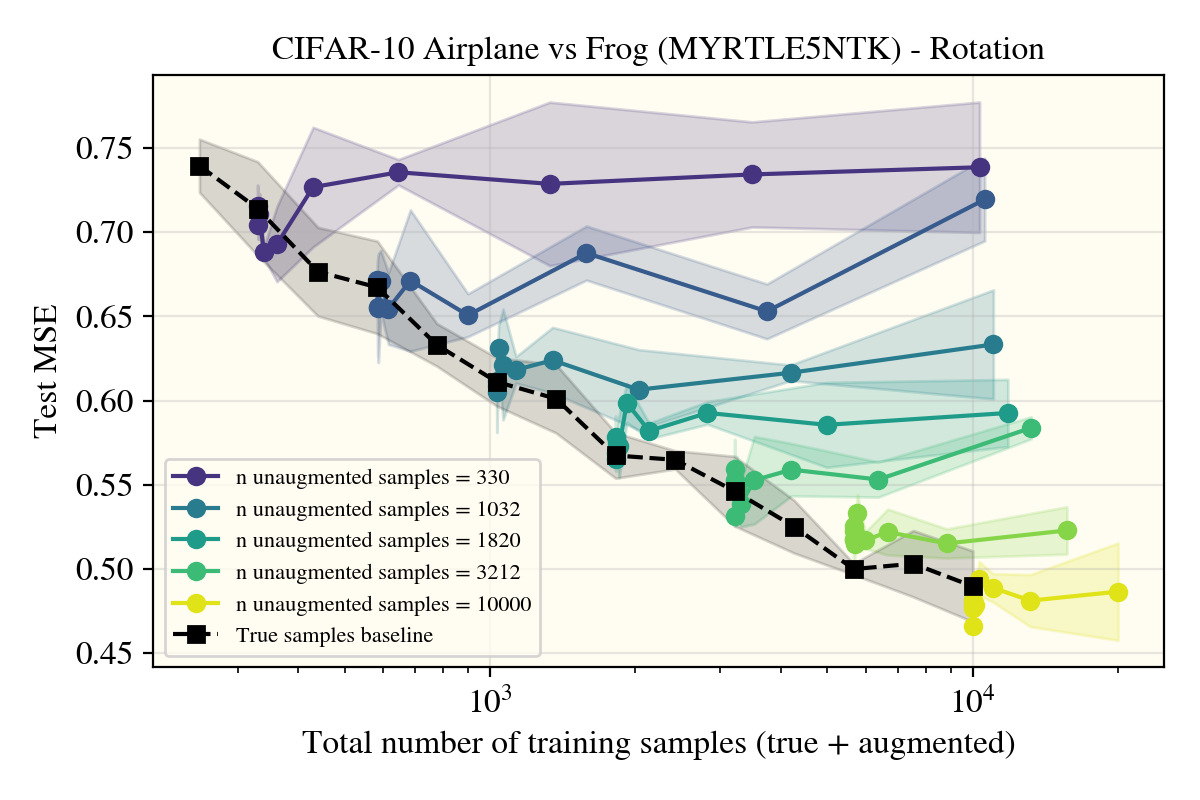
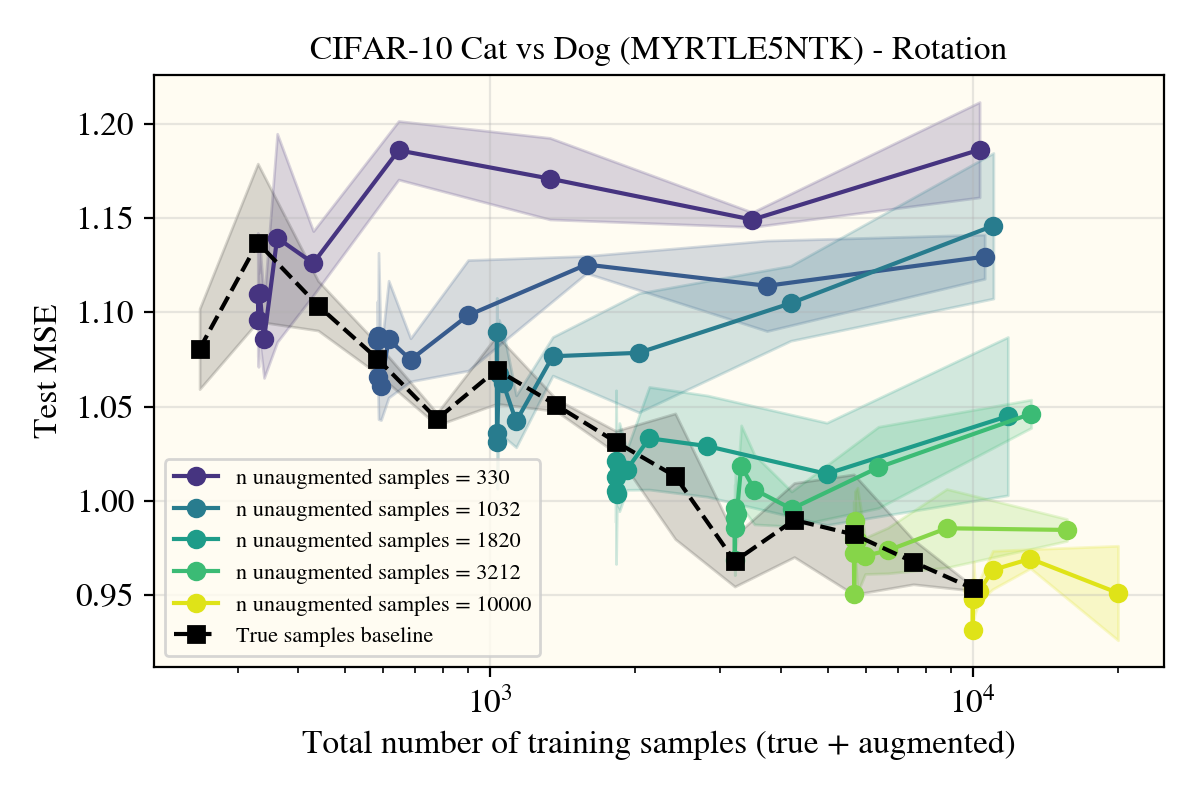
Yet again, there was no strong change in the (scientific) results! The Myrtle5NTK (doesn’t) use the augmented samples in the exact same way that the ReLUNTK did! At this point, I thought perhaps kernels just hated data augments and nothing could be done. Before dropping the line of questioning though, I looked through what type of data augments people actually used, and saw cropping and horizontal flips as some of the most common, most performant schemes.
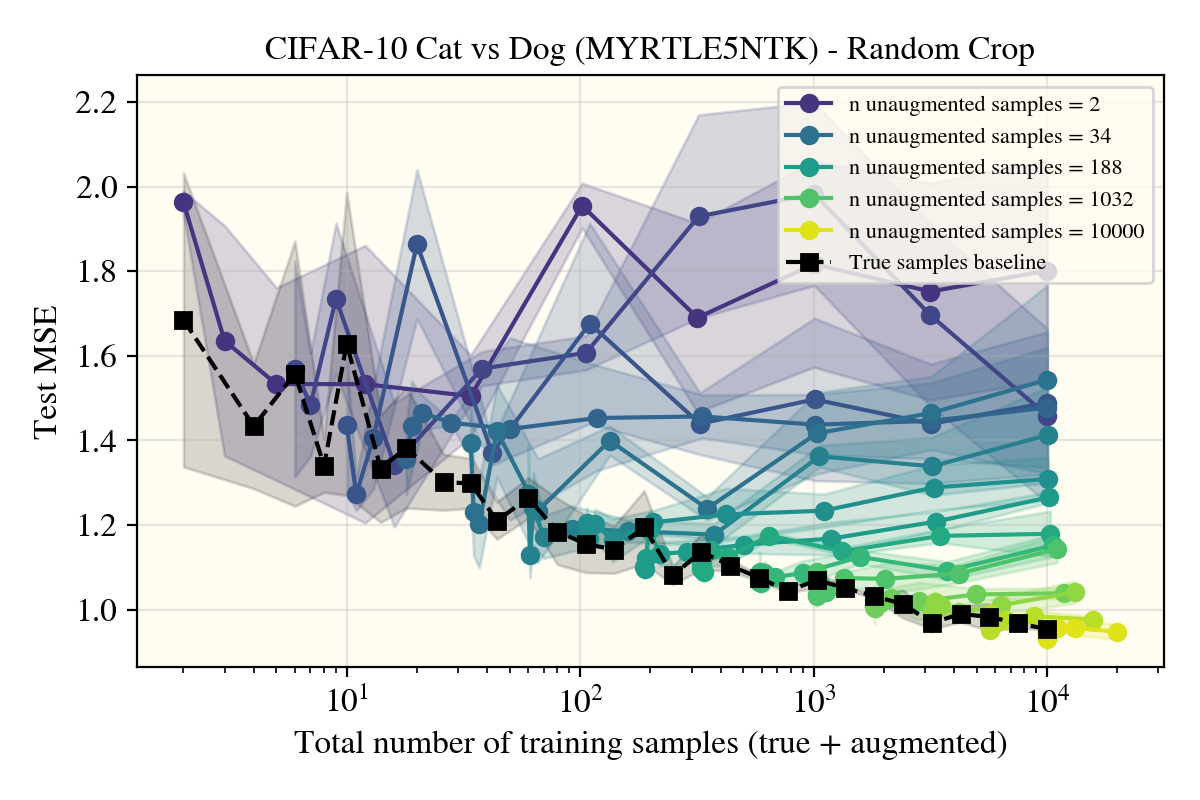
To go over cropping first, as that was a negative result, there was markedly no change between using random cropping and rotations. This could be due to my cropping setup not being ‘correct’ (I used a crop+padding procedure), so note that these results may not hold for a more properly motivated cropping augment.
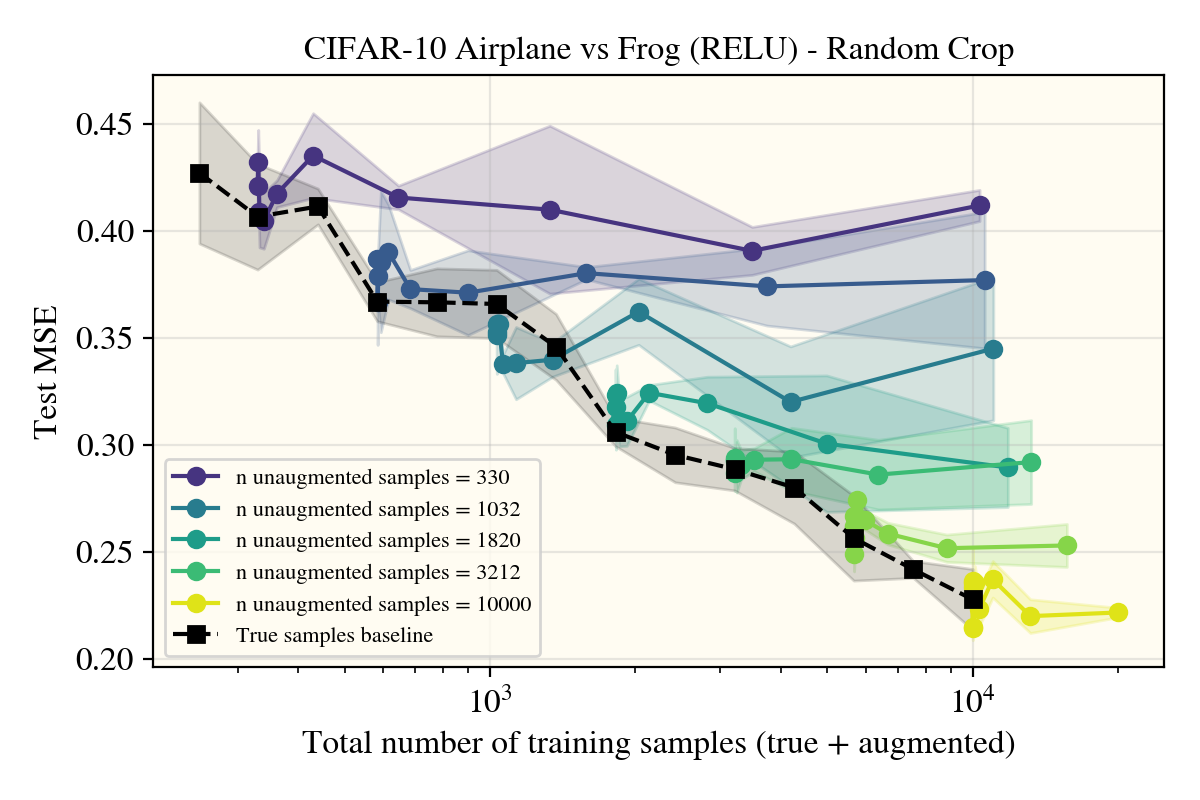
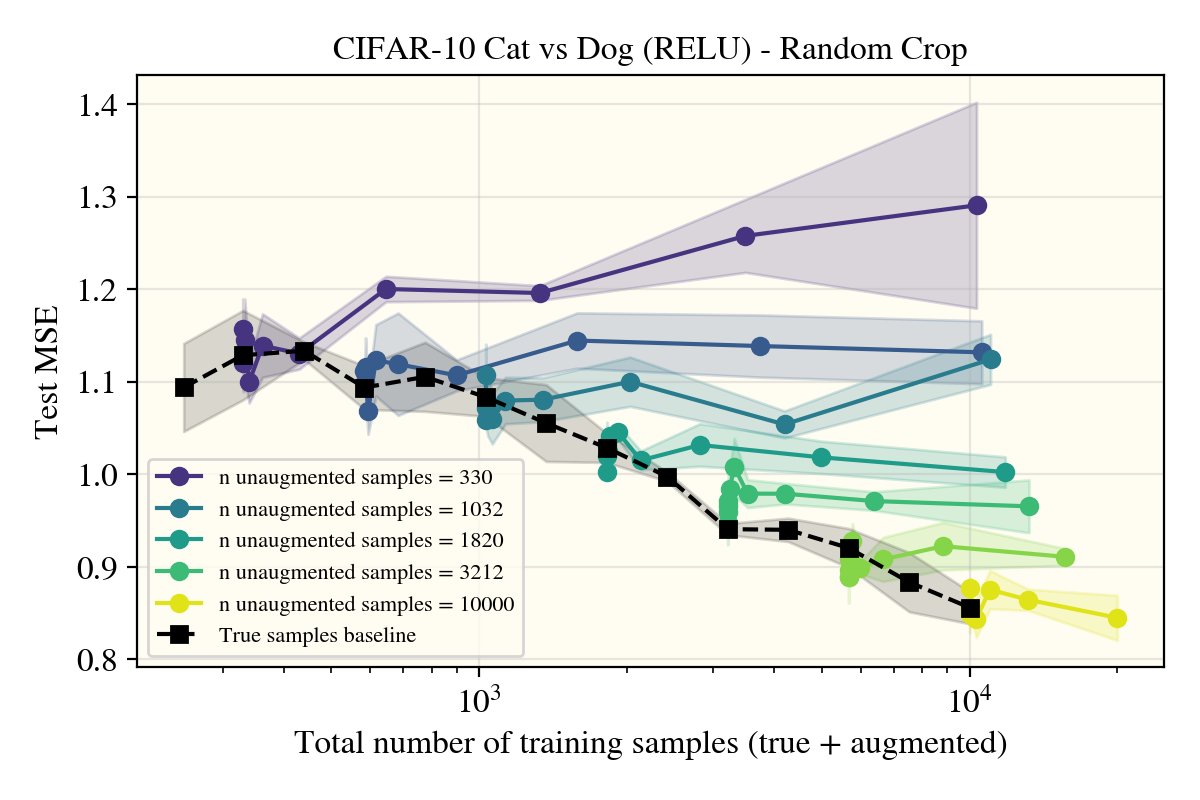
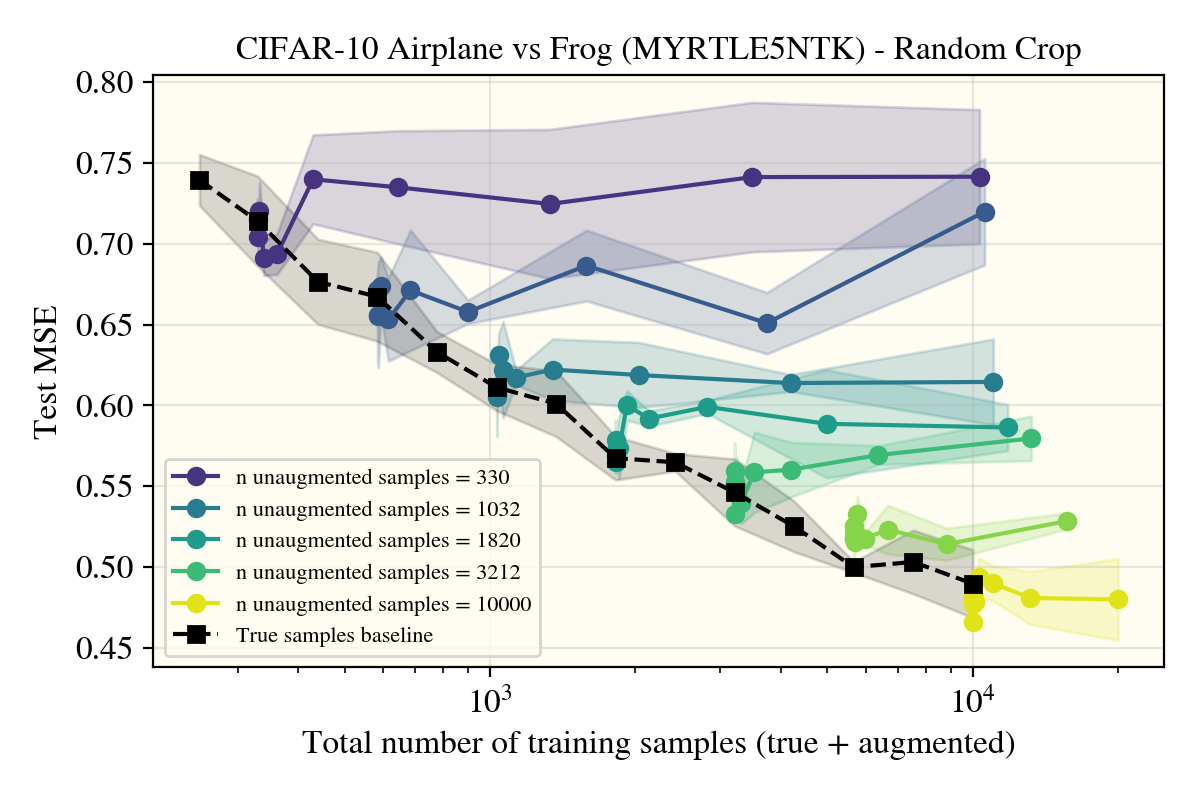
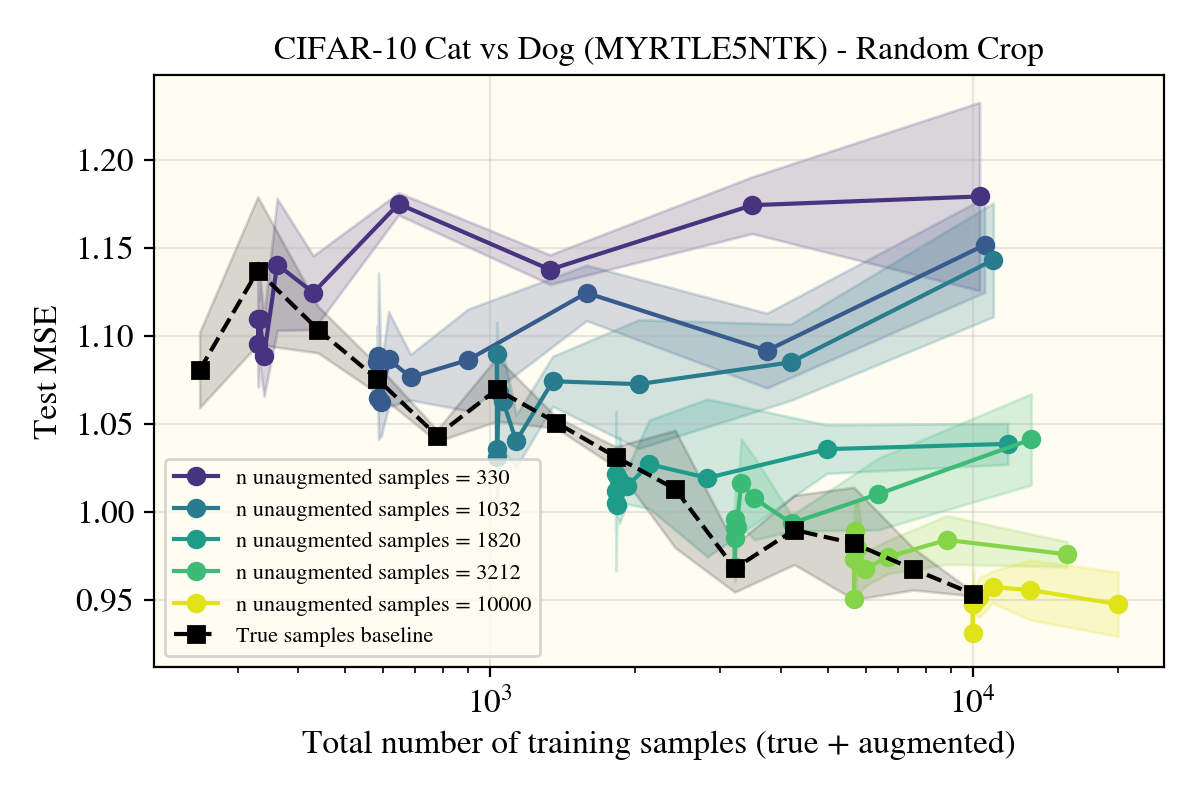
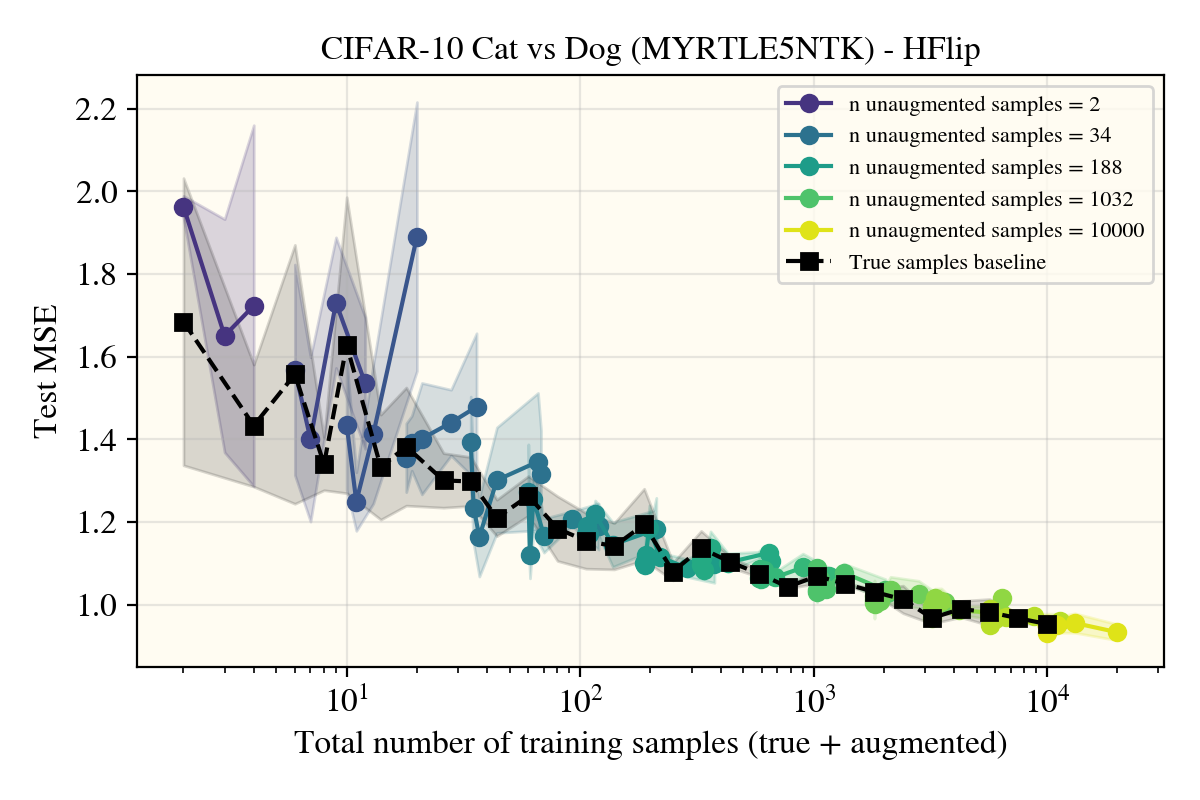
As nothing seemed to do much of anything, I was getting worried there were bugs in my setup that I couldn’t find. Luckily, this doesn’t seem to be the case, as the horizontal flips came to verify:
Horizontal flips
Unexpectedly, horizontal flips were the only data augment (of the ones I tried) that got real performance increases in the models—and not just for the convolutional Myrtle5NTK, but also for the ReLUNTK!
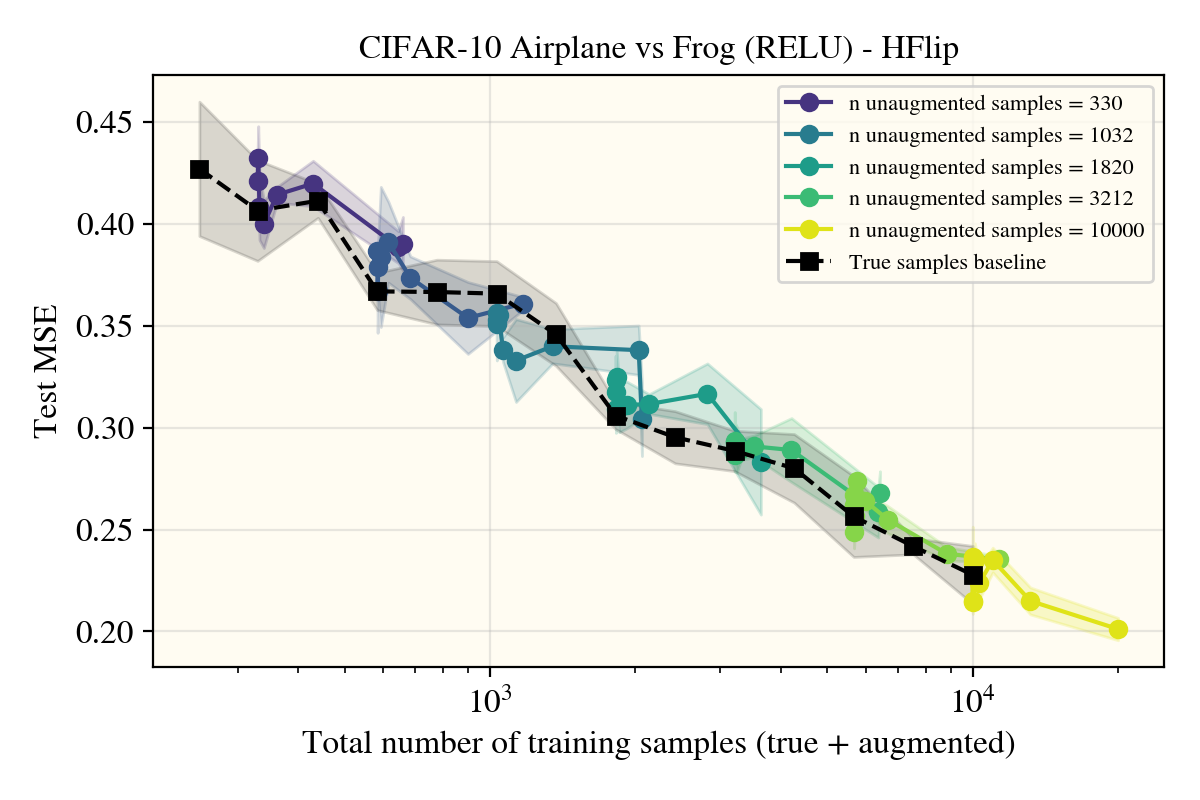
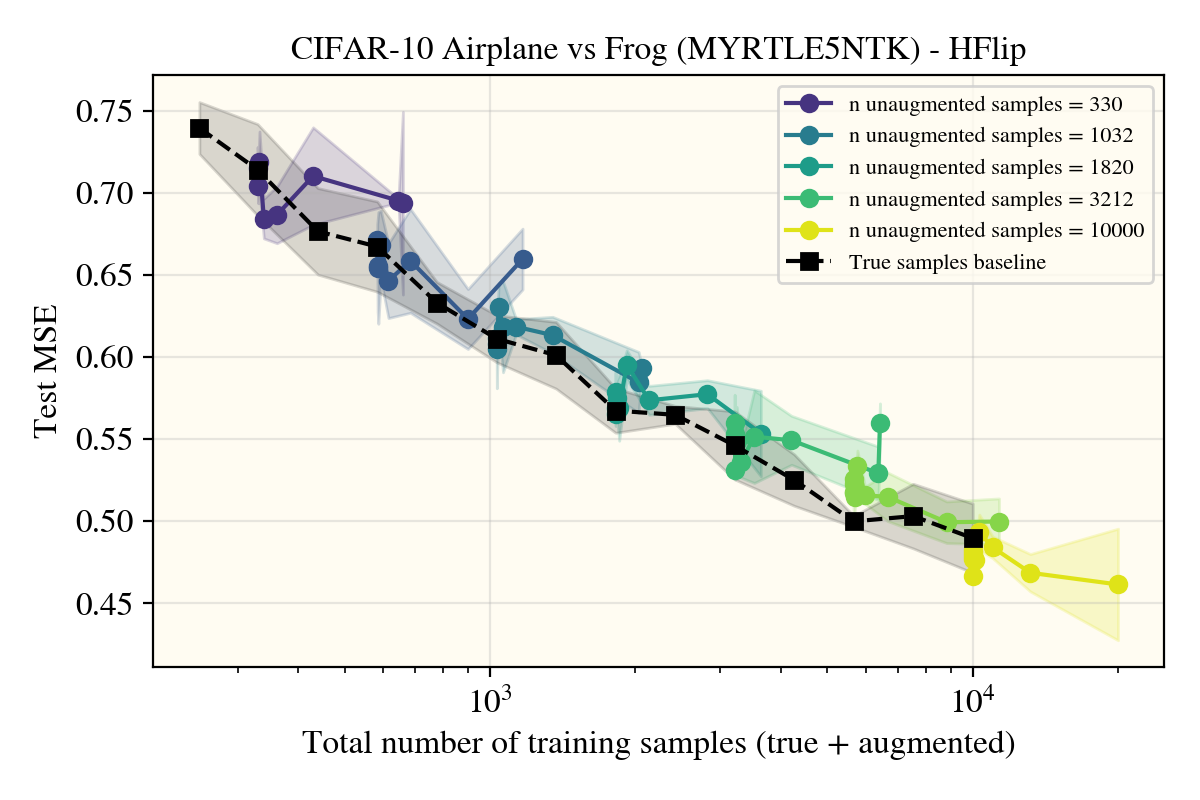
This was really surprising! Not only was this the only augment (I tried) that worked, but it appears that the augmented samples lie well within the 1 standard deviation errorbars I put for the true learning curve in black that only uses natural data! There appears to be something about the horizontal flip procedure that creates realistic images in a way that rotations or random cropping don’t? To investigate, I tried a number of different potential explanations:
Possible Explanation 1: Target function power shifts
As a foreword, this explanation is based off of kernel theory. It’s not important to be ingrained with it, but only the basic idea that lower ‘modes’ of the data are learned first.
The idea here is that horizontal flip augmentations push more of the target function’s power from high to low modes, enough so that the base (unaugmented) n training samples are overall more predictive of the target function. In kernel theory, this means they have a higher ‘eigencoefficient’—the amount of power any mode has in predicting the target function. This only incorporates the data augments into the shift in target function power, and doesn’t specify a change in how many modes are learned, as it is unclear how many to include with data augmentation. As task nor model appear to affect results, I went with a ReLUNTK trained on airplane vs frog, finding that indeed the first n modes have, on average, higher eigencoefficients… the issue is, this also appears even for rotations and random cropping (not shown to save on space).
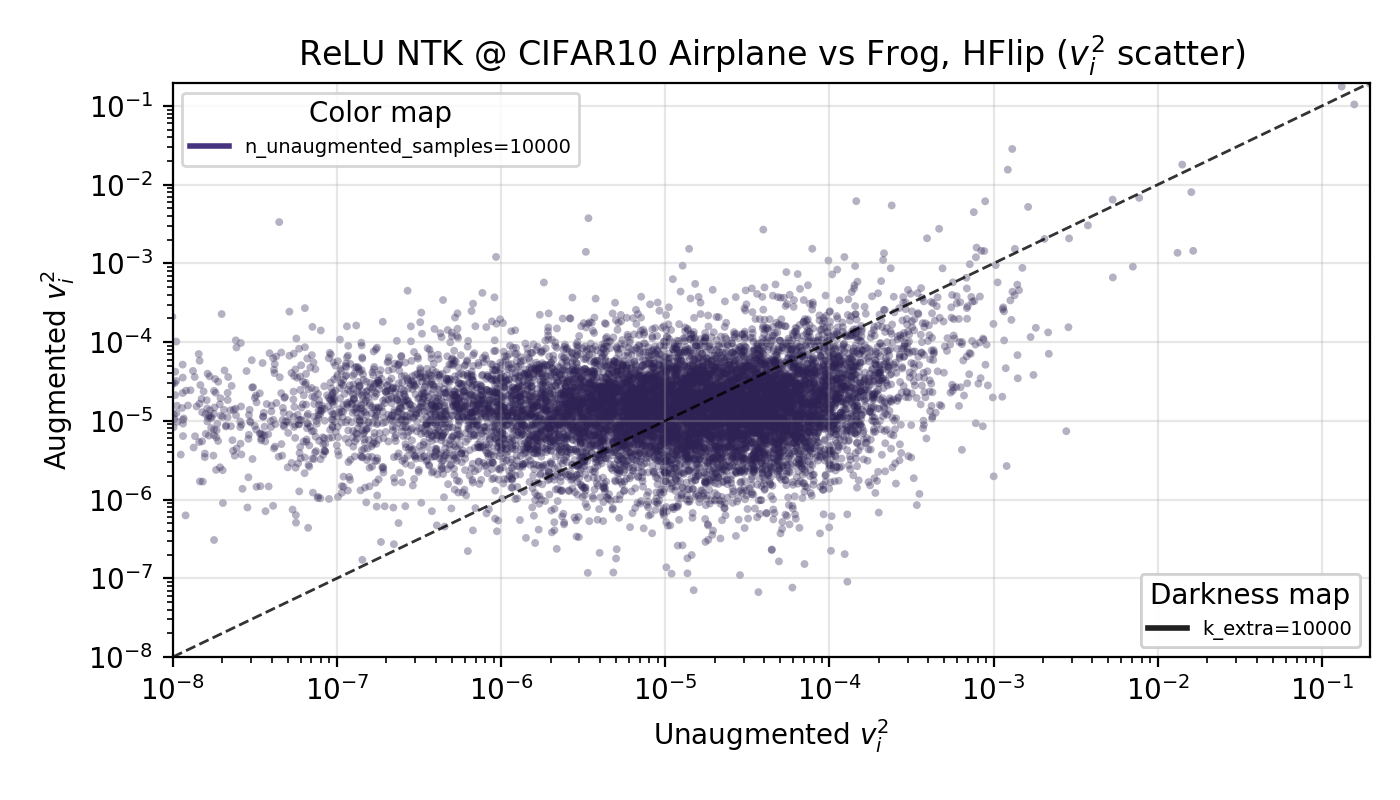
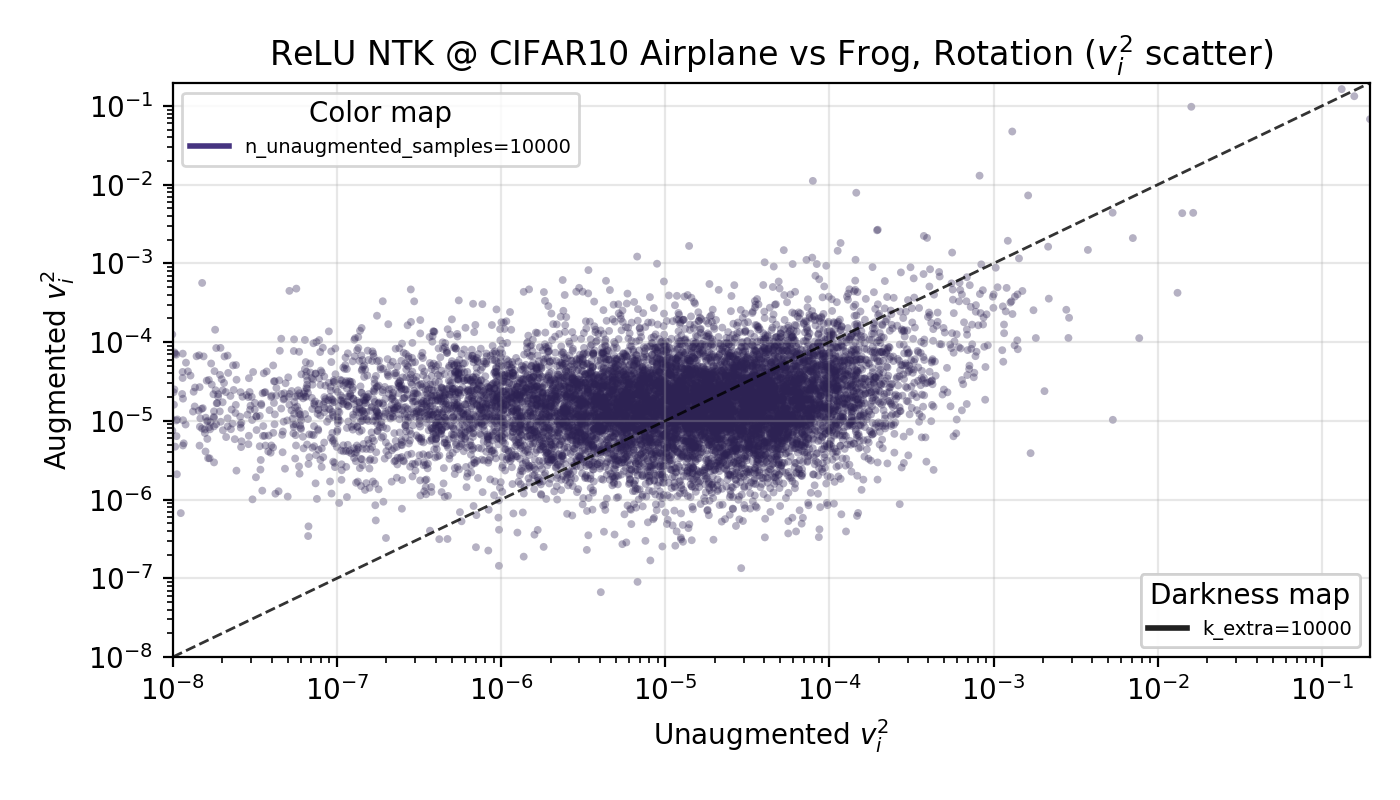
Since there isn’t any notable change between the horizontal flip case and the rotation case, let’s say this explanation isn’t true. There’s likely some effect on the number of samples to use in the kernel theory when performing data augmentation that I haven’t thought through, although it seems like an uphill battle to quantify given these results.
Possible Explanation 2: Data augments help learn different features
Perhaps the eigencoefficient story is missing the important part: the features themselves. Regardless of what happens with the eigencofficients, we should also look at the features (eigenvectors) of our kernels to see the effects of data augmentation. It’s plausible that data augmentation drastically changes the low-level features of the model and this is somehow (in a way I’m leaving handwavy for now) increasing the performance. To test, I ran a high-n ‘base case’ for what the eigenvectors of a trained kernel on and compared the (eigenspace) overlap between a base feature and a neighborhood of features from the data-augmented kernel. A baseline of a random resampling was used to compare results against. To avoid fuzziness, I will plot the cumulative overlaps from feature (eigenvector) 1 to the index. The experiements were performed on the cat vs dog subset with the Myrtle5NTK, but I highly suspect results hold more broadly.
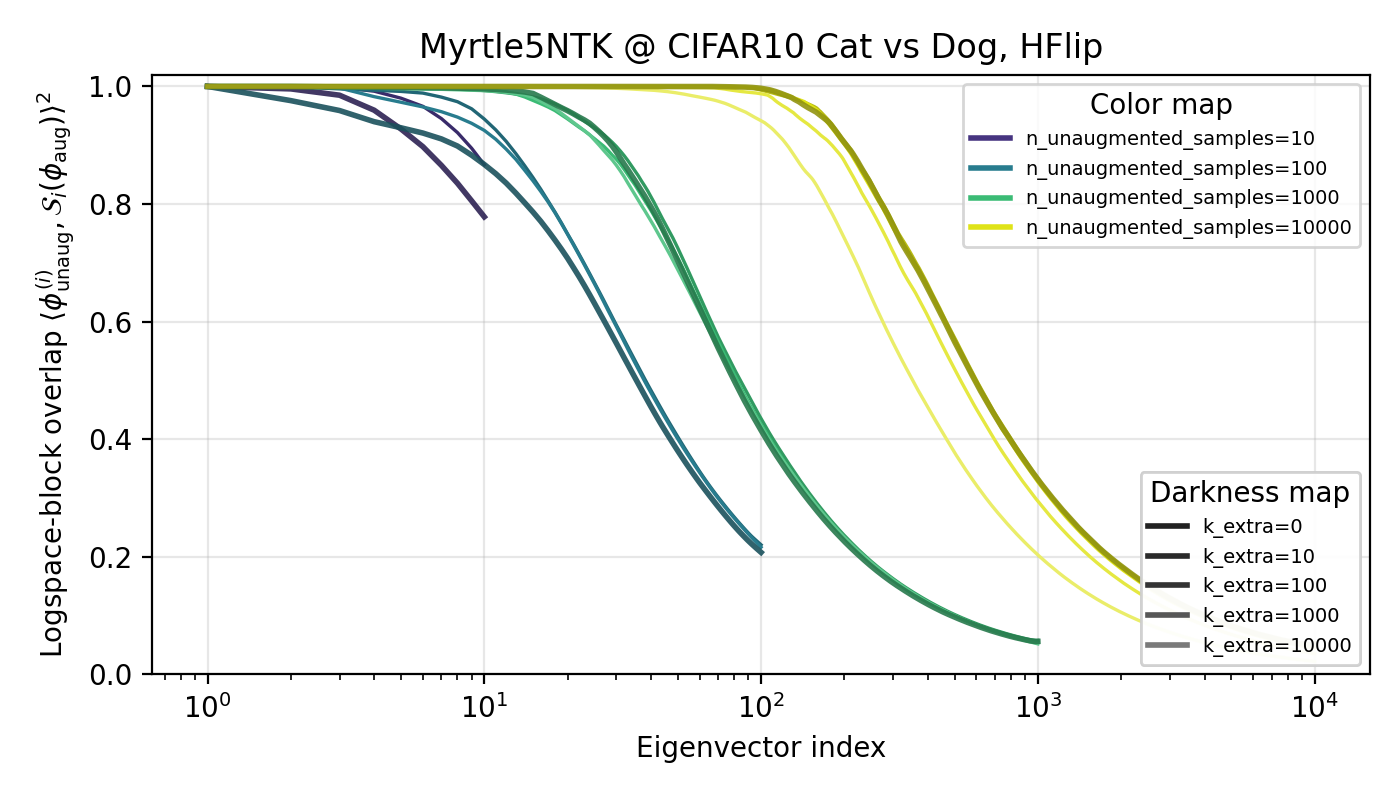
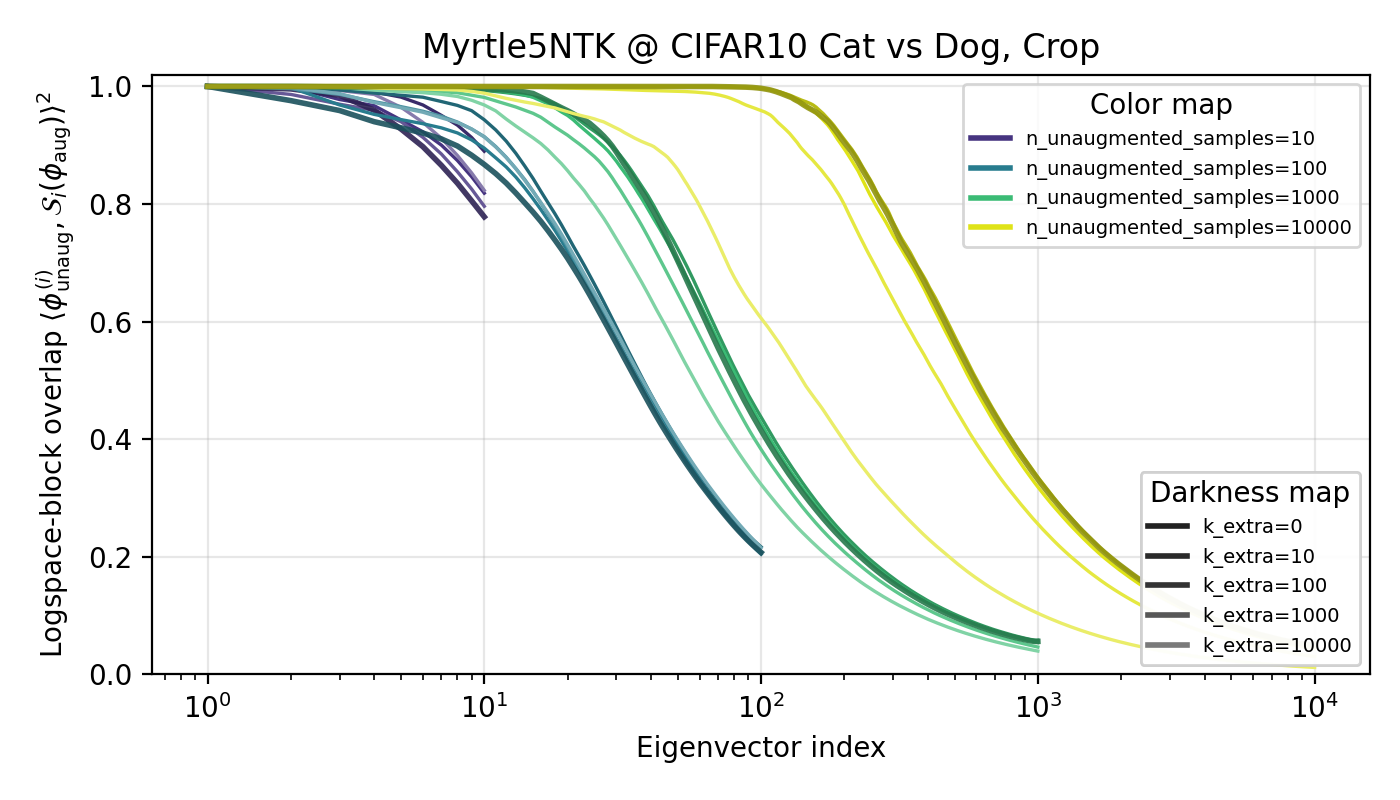
Interestingly, there is higher overlap between the eigenspaces of the kernel with horizontal-flip data and the baseline compared to that of the random cropping (and rotation which is not shown but results are similar) kernel(s)! This went against my initial rationale, but I don’t have a great explanation as of now why that is.
Sendoff
It’s clear there’s still more work to be done here! This is not my current research focus though, so for now I will leave it here. I’m hopeful that more work on data augmentation can/will be done using this line of reasoning.
Appendix
A: Additional kernel experimentals
All datapoints presented in this blogpost are taken over 3 random initializations. Unless otherwise specified, all kernels are run with a ridge regularization of 0.001.
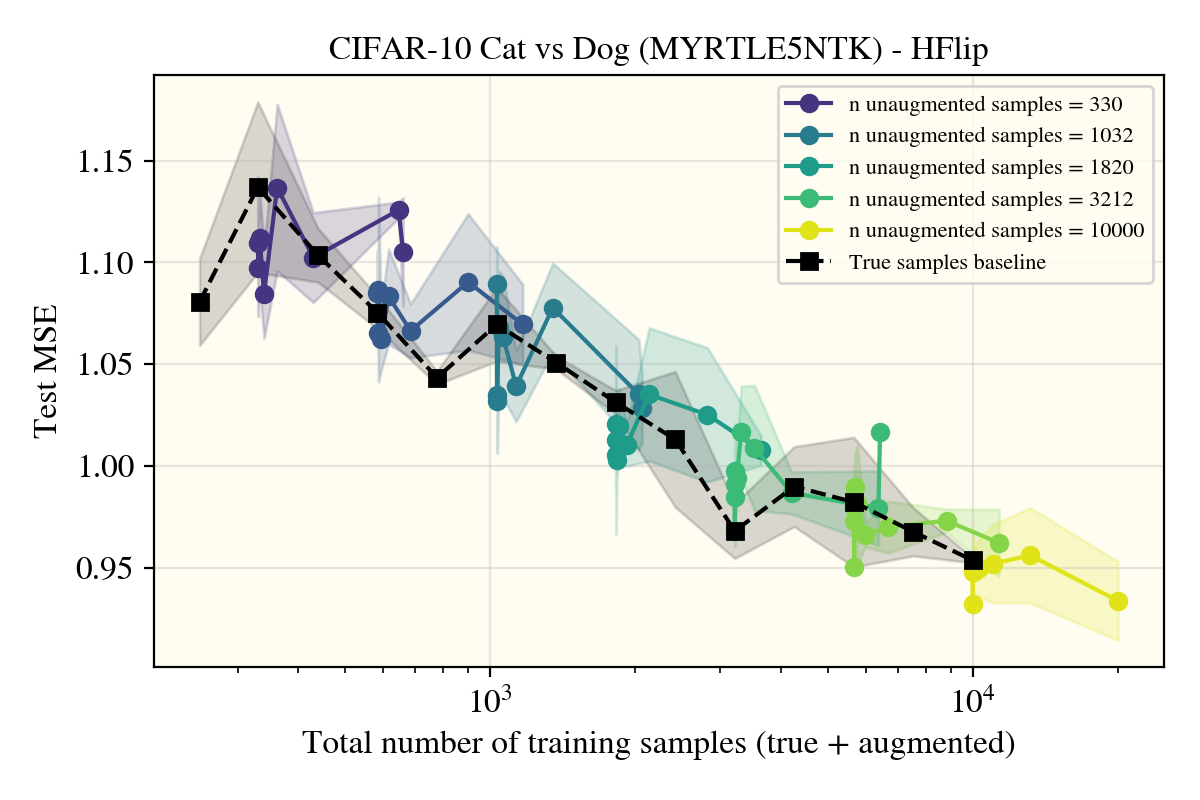
The plots I’ve detailed have been zoomed in on the results above 200 samples; while I have train runs below 200, I don’t include them to reduce visual clutter. However, the lower sample behavior doesn’t change the overall narrative, as is shown below: